
Shader Core
Diving down a little deeper, the 240 shader processors are split into ten texture (or thread, in compute mode) processing clusters.These are then further split into three groups of eight shader processors along with combine an instruction unit and 16KB of shared local memory – they’re known as streaming multiprocessors (SMs) as we discussed earlier on.
This is where most of the 3D graphics (and just about all of the general compute) performance comes from; obviously, there are other factors and limitations that determine performance in real applications, but you can think of it as the engine room.
On top of this, each texture processing cluster also has eight texture units that can handle eight texture addresses and eight bilinear texture filters per clock. These run at 602MHz in the GeForce GTX 280 and deliver a combined texture fill-rate of 48 gigatexels per second.
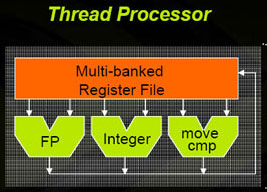 Inside each streaming multiprocessor, there is also a multi-banked register file, which has been doubled in size compared to the GeForce 8- and 9-series GPUs. The reason for this, Nvidia says, is that there are situations—both in 3D and general compute operations—where the GPU often ran out of register space, meaning it had to swap data out to memory – this is not ideal because, while the SM is waiting for data to come back from memory, it can stall and that can cause some serious performance implications.
Inside each streaming multiprocessor, there is also a multi-banked register file, which has been doubled in size compared to the GeForce 8- and 9-series GPUs. The reason for this, Nvidia says, is that there are situations—both in 3D and general compute operations—where the GPU often ran out of register space, meaning it had to swap data out to memory – this is not ideal because, while the SM is waiting for data to come back from memory, it can stall and that can cause some serious performance implications.The instruction unit manages groups of 32 parallel threads – Nvidia calls these 'warps' and each instruction unit can handle 32 warps, making a total of 1,024 threads in flight per streaming multiprocessor. As there are 30 SMs inside GT200, this means the chip can handle up to 30,720 threads at any given time – this is up from G80's peak throughput of 768 threads per SM and 12,288 for the whole chip.
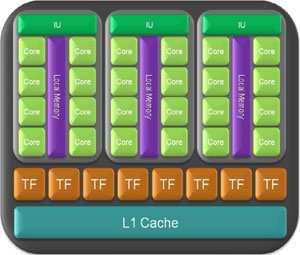
A GT200 Texture Processing Cluster
If a particular thread is waiting for a high latency task (such as a texture read or memory access) to complete, the multithreaded instruction unit can switch to another warp at no cost – this helps to hide latency and prevent the stream processors from sitting idle or, even worse, stalling.
One of the standout features on the long list of architectural improvements made in GT200 was the significant size increase Nvidia has applied to the stream out buffers. Nvidia documentation claims that the internal output buffer structures have been upsized by a factor of six, which should help to make the geometry shader more accessible to developers who want to use it to generate lots of data in tasks like tessellation.
How fast is the new shader core though? Well, there's only one way to find out...
Aside from the strange result for the Radeon HD 3870 X2 in RightMark 3D 2.0's Parallax Mapping test (which is probably down to the Radeon HD 3870 X2 being slightly texture limited in some respects), things add up - the GeForce GTX 280 is a brute when it comes to general pixel shader tasks. Of course, much of this is down to the increased shader count, but some of the performance increase is attributed to the improved register file size.
Interestingly though, both the GeForce 9800 GX2 and Radeon HD 3870 X2 are faster in 3DMark06's Perlin Noise test. This is probably down to the fact that the shaders aren't quite as complex as they are in 3DMark Vantage's updated version of the test and, as a result, the register files aren't quite so full which negates any potential benefits from the beefed up units.
RELATED ARTICLES







MSI MPG Velox 100R Chassis Review
October 14 2021 | 15:04

Want to comment? Please log in.